Hace unos años se hizo evidente que el complemento de ADN del
muy estudiado virus FX174 no era lo suficientemente grande para codificar todas
las proteínas producidas por este virus en su bacteria parasitada. La
sorprendente solución a este problema sólo ha descubierto otro problema, es
decir, el de los genes superpuestos.1 Se ha descubierto que en
la cadena circular de ADN de este virus la parte que codifica la proteína A
tiene sobrepuesto el gene B que codifica la proteína B. Asimismo, el gene E está
sobrepuesto al gene D. Además, hay aparentemente otro gene, A*, sobrepuesto a
los dos genes A y B. De esta manera este virus fago compensa la escasez de
letras de codificación en su mensaje ADN haciendo un uso múltiple de las partes
de ADN que posee.
Todo esto es ya sorprendente por sí mismo, pero aún más asombroso es el hecho
de que en los casos de los genes A y B y de los genes D y E, los pares
sobrepuestos de genes son leídos en diferentes marcos de lectura. Recordemos que
el código genético del ADN emplea un alfabeto de cuatro diferentes nucleótidos
que son las letras del código del ADN. Los nombres de los cuatro nucleótidos,
adenina, timina, guanina y citosina, se abrevian con las letras A, T, G, C. El
diccionario genético de palabras que expresan los veinte diferentes aminoácidos
que constituyen las cadenas polipeptídicas de proteína contiene palabras de tres
letras designadas como codones. De manera que un gene que codifica una proteína
determinada se compone de una cadena de codones de tres letras de código cada
uno, y que la maquinaria de transcripción de la célula traduce a una cadena
polipeptídica de los correspondientes aminoácidos. El gene, entonces, puede ser
asemejado a una oración de palabras de tres letras que da un sentido correcto
cuando se leen sus instrucciones y son puestas en ejecución con la construcción
de una molécula de proteína designada para una tarea específica en la vida de
una célula. Pero si un segundo gene está sobrepuesto sobre el primero y si se
lee en un diferente marco de lectura, resultará una secuencia diferente de
aminoácidos, con una molécula diferente de proteína designada para una tarea
totalmente diferente.
La mente se queda aturdida ante esto, cuando se considera la analogía del
lenguaje humano. Piénsese en intentar construir siquiera una breve oración
castellana con significado que pueda transformarse en otra oración con
significado y gramaticalmente correcta sólo desplazando el espaciado una letra
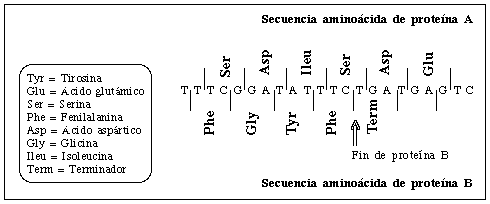
hacia la derecha o hacia la izquierda. En la ilustración se ve una breve porción
de los genes sobrepuestos A y B del FX174, con los correspondientes aminoácidos
traducidos en los dos marcos de lectura.
En base del modelo evolucionista, estos dos genes llegaron a su presente
contenido de información por medio de mutación y selección natural, de modo que
ahora codifican las dos proteínas, A y B, que llevan a cabo sus funciones
específicas. Se supone que las letras individuales mutaron a otras letras, y que
la selección natural actuó sobre las proteínas alteradas resultantes. De esta
manera, algo de la cadena ADN original evolucionó gradualmente para constituir
la actual, que incluye la sección de 360 letras que codifican a los 120
aminoácidos de la proteína B, sección ésta incrustada en el seno de las 1536
letras que codifican a los 512 aminoácidos de la proteína A. De modo que en esta
sección que efectúa su función de doble codificación, a lo largo del dilatado
proceso evolutivo, cada mutación de cada letra solitaria era por lo general una
mutación en cada una de las dos proteínas. En tal caso, la selección natural
tuvo que actuar sobre los correspondientes cambios en ambas proteínas,
seleccionando aquellas mutaciones que en conjunto producían una ventaja para el
virus fago. Los dos resultantes mensajes sobrepuestos en el ADN tienen sentido y
son gramaticalmente correctos en el lenguaje genético de modo que ambas
proteínas son apropiadas para sus tareas específicas. Un proceso así es ya
difícil de imaginar para un gene ordinario, pero los problemas desde luego se
complican en estos genes sobrepuestos.
Según Yockey, el máximo contenido en
información del ADN empleando el código genético es de 4,153 bits por codón,2 y el contenido en información del citocromo C es de 2,1376 bits
por residuo de aminoácido.3 Pero si dos proteínas que tienen
genes superpuestos en diferentes marcos de lectura tienen alrededor del mismo
contenido de información, digamos que 2 bits por residuo, entonces el ADN ha de
llevar unos 4 bits por codón. Esto está peligrosamente cerca del límite teórico
de 4,153 bits por codón, lo que sugiere unas limitaciones sumamente estrictas
para la variación de los dos mensajes superpuestos y hace difícil creer que los
dos genes superpuestos se originasen por mutación y selección natural. Con un
contenido de información de 4 bits por codón, el segmento de 130 codones que
codifican la proteína B incrustados en el gene para la proteína A tiene un
contenido de información de 4x130 = 520 bits. La probabilidad para su formación
al azar es
p = 2-520 = 10-156,6
Pero esto es sólo una parte de la historia, porque los genes se hallan bajo
limitaciones adicionales. Han de llevar información superpuesta para otras
funciones como uniones y emplazamientos de inicio para la reproducción del ADN,
transcripción del ADN a ARNm y traducción de ARNm a proteínas, así como la
ejecución de otras demandas de los genes y de las moléculas de ARNm. La
credulidad se estira hasta el punto de rotura bajo la pretensión de que los
sistemas genéticos son productos espontáneos carentes de plan y propósito.
Conclusión
Las probabilidades matemáticas calculadas para la abiogénesis, en base de las
propiedades termodinámicas de las proteínas y de los microorganismos y del
contenido de información de las proteínas dan un número abrumador de
imposibilidad. Los análisis del contenido de información de estructuras
biológicas complejas como el cerebro humano dan una probabilidad aún más pequeña
de formación al azar. Finalmente, la consideración de sistemas genéticos
complejos como el de los genes sobrepuestos lleva a resultados similares. De
modo que el creacionista bíblico tiene amplia ilustración en la biología para su
creencia de que sin una creación especial de parte de Dios, la probabilidad de
la vida es de cero. Podemos decir, con el salmista: <<... asombrosa y
maravillosamente he sido hecho,>> <<Sabed que Él, el Señor, es Dios;
Él nos hizo, y no nosotros a nosotros mismos ...>>.4
REFERENCIAS
1 F. Sanger, et al., Nature, 265, 24 Feb. 1977, págs.
687-695. Volver al texto
2 Hubert P. Yockey, J. Theor. Biol. (1974) 46, pág. 381.
Volver al texto
3 Hubert P. Yockey, J. Theor. Biol. (1977), págs.
386-387. Una ligera corrección en los cálculos de Yockey lleva a este resultado.
Volver al texto
4 Salmo 139:14 y Salmo 100:3, Biblia de las Américas. Volver al texto
Robert Kofahl tiene un doctorado en química. Sirvió primero como miembro de
la facultad de Highland College en Pasadena, California, y luego como su
Presidente. Desde 1972 ha sido Coordinador Científico del Creation-Science
Research Center en San Diego. Entre otras obras es coautor, con Kelly Segraves,
de The Creation Explanation.
Fuente: Repossess the
Land, Simposio 12-15 agosto 1979, págs.
125-126.
 Volver a índice de Génesis
3
Volver a índice de Génesis
3
De vuelta al índice
general
De vuelta a la página
principal
© SEDIN 1997